
Demystifying Distributed Checkpointing
Improving efficiency of LLM training workflow

Preface: why did I pick this topic?
Recently, a good friend suggested that given my background and interest in infrastructure, I should explore ML training infra. I had the impression that this area is very academic and something I’d struggle to grasp without a refresher on linear algebra and ML frameworks. While that’s all true, a specific topic that caught my attention is distributed checkpointing. After a bit of Googling, it turns out that aside from academic papers and a couple blogposts from ML researchers, there aren’t that many writings on this topic written by, or tailored to, infrastructure and system engineers. So here I am, kicking off my Substack newsletter to discuss distributed checkpointing in LLM training workflows from the lens of an infrastructure engineer.
Checkpoint and ML
Checkpointing is a familiar mechanism for folks that have worked with stateful systems — the idea of storing a snapshot of the current state of a system, so if the system stops or crashes, it can be restored to that state. From database crash recovery, to save files in video games, to web-based tools with auto-save and version history features like Figma, Notion and Google Docs, checkpointing is a well-applied mechanism.
What does checkpointing have to do with ML? An LLM training workflow is a massive data pipeline that takes weeks or even months to complete. Since it’s also an active field of research, it tends to be an iterative process that combines automated tasks with hands-on tweaks as researchers continuously experiment and fine-tune model performance. And when issues like overfitting or training instability are detected, the model may be rolled back to a previous checkpoint, discarding work completed after that point. As a result, periodic checkpointing is essential to minimizing waste of compute resources.
Checkpoint with GPUs
A typical GPU instance consists of both CPUs and (typically up to 8) GPUs — CPUs handle general processing tasks, while GPUs focus on highly parallelizable matrix operations. While each GPU has dedicated memory (VRAM), the machine is typically equipped with significantly more main memory (RAM) accessible to the CPUs.
A common approach to performing a checkpoint consists of three high-level steps:
Copying current training state from VRAM to RAM (known as Device-To-Host copy, or D2H copy).
Serializing state into compact byte objects.
Dumping serialized objects to disk or remote persistent storage.
Why not just directly serialize and store GPU state to disk? It turns out that transferring data from VRAM to RAM is relatively performant, leveraging high-bandwidth PCIe lanes to maximize throughput and minimize latency. In addition, not all hardware supports directly writing GPU state to disk; and even if they did, having GPU tied up to disk- or network-bound operations is suboptimal for resource utilization.
It’s worth noting that step 2 and 3 are often executed asynchronously, allowing GPUs to resume training tasks immediately after the state is offloaded to main memory (see PyTorch’s async_save, for example).
Checkpoint, distributed
State-of-the-art LLM training workflows are distributed over hundreds or even thousands of machines. ML engineers have coined the term “3D parallelism”, representing the 3 dimensions used to shard the training workflow across machines:
Data Parallelism (DP): shard the input data into batches, with each batch of data trained on the entire model.
Pipeline Parallelism (PP): shard the model into sequential layers, making it possible to train with very large models that cannot fit on a single machine.
Tensor Parallelism (TP): shard each layer of the model into separate compute units, allowing more parallel execution within a layer.
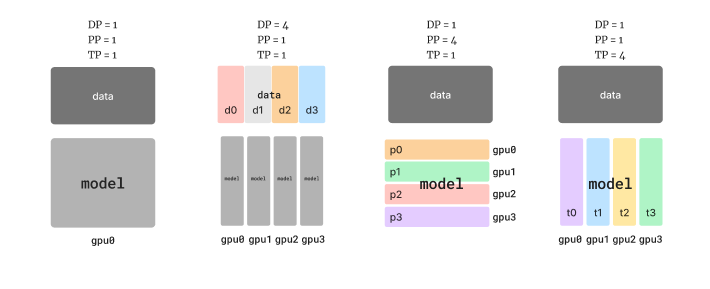
A combination of these sharding mechanisms are used to improve training efficiency.
A natural question is, could we just have each node periodically perform its checkpoint independently, in a way that’s no different from single-node checkpointing? This is known as uncoordinated checkpoint; and if these nodes never have to communicate with one another, this approach would be just fine. However, LLM training requires frequent communication and synchronization across nodes (known as collective communication). For example:
Sharding input data into batches means we need to later aggregate the results across nodes (i.e. averaging the gradients)
Sharding the model into layers means we need synchronize data relayed from one layer to another
Sharding a single layer means each tensor shard must exchange its results with other shards to ensure computation is complete.
Having a consistent global training state for checkpointing is critical to the correctness and effectiveness of the training process, so we need mechanisms to synchronize state across shards.
Good ol’ barriers
Barrier is a classic synchronization technique in distributed systems. For example, distributed processing engine like Flink implemented a variation of the Chandy-Lamport algorithm known as asynchronous barrier snapshotting. The core idea is to periodically insert a barrier event into each parallel stream, and when a downstream task joining the parallel streams receives a barrier event from one of them, it waits for all other barriers to arrive. At that point it can safely take a consistent snapshot and then resume to processing.
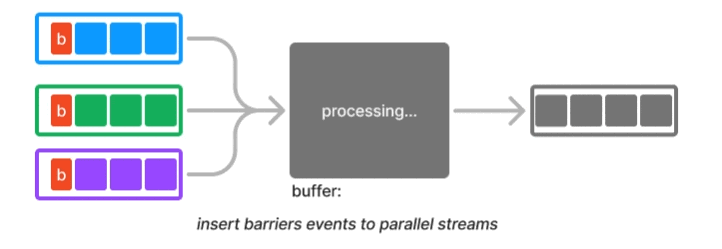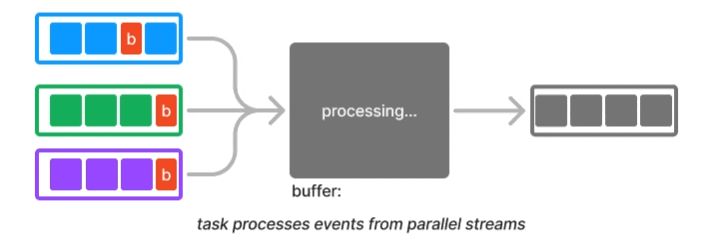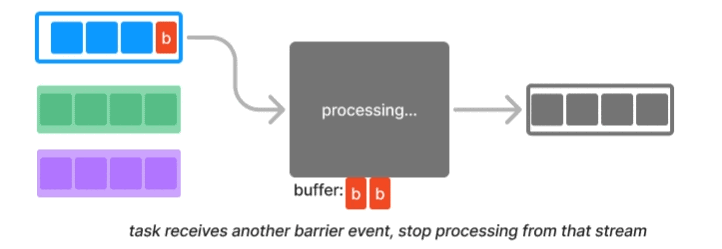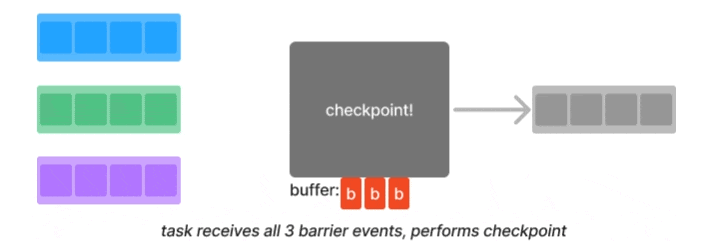
In LLM training workflow, barriers are used as a synchronization technique when nodes don’t need to exchange data. However, LLM training often requires data exchange due to 3D parallelism discussed earlier. This is where an operation called AllReduce plays a critical role in synchronization. The gist is that each node gathers necessary data from other nodes, performs an aggregation, and then broadcasts the aggregated result back to all other nodes.
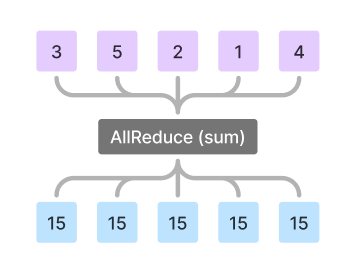
Broadcasting here is inherently a synchronization mechanism, as each node waits for results from all other nodes, which is why checkpointing is often performed after an AllReduce operation.
So does this mean distributed checkpointing is a solved problem? It turns out that as the LLM training state grows with the size of the model, checkpointing becomes increasingly challenging due to memory constraints, network congestions, limited bandwidth of storage I/O, rising failure rates, and increasingly wasted compute; all in ways that are familiar to engineers working on traditional large-scale infrastructure. Plus, reducing time spent performing checkpoint/restore is an important optimization to accelerate training iterations, much like reducing build and CI times to enhance developer productivity.
Let’s dive into a few active areas of research.
Full vs. incremental checkpoint
Today’s LLM training workflows primarily rely on full snapshots for checkpointing. So it’s natural to wonder: can we take an incremental snapshot instead where we only record deltas from the last snapshot to a change log? After all, in database technology, we’ve leveraged the tried-and-true concept of write-ahead logging to record changes. It turns out that because of the massively parallel computation, the matrices receive very dense updates (especially during the pre-training phase), so recording incremental changes can be even more costly than a full snapshot — after all, an incremental change event contains not only each delta, but also metadata specifying where the change happened so it can be reapplied later. Still, with the promise of change log, and the idea that snapshot can be reconstructed offline, there has been some research into incremental checkpointing. If feasible, the amount of time GPUs spend on checkpointing tasks can be significantly reduced, which seems like a worthy pursuit (side note: I can’t help but find some resemblance to the design of NoSQL databases using log-structured merge-tree to asynchronously merge the changes on disk to support write-heavy systems).
Another related approach is a fuzzy snapshot, where full snapshots are taken at a loosely defined time across shards to avoid synchronization completely. This combines uncoordinated snapshotting with a change log; meaning the global state of a snapshot across nodes is not consistent by default, but the recorded changes can be applied to bring it back to a consistent global state. This removes the overhead of synchronization during save, but introduces new complexity upon restore. For example, as you apply the changes, how do you determine when you have reached a consistent global state? Nonetheless, if feasible, the amount of time GPUs spend on checkpointing tasks may be reduced from “synchronization + D2H copy” to just D2H copy, which is also quite appealing.
In-memory checkpoint
So far, the optimizations discussed above target reducing the overhead of taking a snapshot. However, restoring a checkpoint can still be bottlenecked by disk or network I/O, often taking tens of minutes to restore a previous checkpoint.
To address this challenge, a recent approach uses a hierarchical storage topology consisting of local in-memory snapshots, remote in-memory snapshot replicas, and less frequent remote storage snapshots to enhance redundancy. To prevent starving training traffic caused by frequent in-memory checkpoint, the checkpoint traffic is pipelined so that it can be interleaved with training traffic. To ensure the checkpoint state is still consistent, each GPU reserves some of its memory to buffer the checkpoint state, with the remaining memory allocated for training workloads.
Sounds familiar? First, this architecture resembles high-availability systems in traditional distributed systems and cloud infrastructure to guarantee uptime and graceful failover when one or more server crashes. Second, the interleaving of training and checkpointing traffic is essentially a scheduling optimization in order to avoid starvation of either task, with model consistency as an invariant.
Sharding and resharding
A more recent challenge in distributed checkpointing is that checkpoints need to be saved in a way that enables easy resharding upon restore. There are many reasons why this is useful:
When transitioning between phases in the training workflow (i.e. from pre-training to fine-tuning phase), the model parameters or data size may change, benefiting from less parallelism.
When performing evaluation or debugging, the models don’t need to be updated, also benefiting from less parallelism.
When resources are elastic, the ability to dynamically adjust parallelism leads to better cost optimization.
This is where the storage architecture of the checkpoint becomes significant, because the schema needs to be flexible enough to support changes to the sharding scheme. Today, some training frameworks already support resharding. However, they are not typically compatible with other frameworks. So when researchers want to use Megatron-LM to perform training, and then PyTorch to perform evaluation, they have to implement custom conversion scripts.
One novel approach is to ensure the snapshotting process generates a framework-agnostic global checkpoint metadata file. This allows the checkpoint coordinator, which orchestrates the restoration, to redistribute work based on a new parallelization config.
When working with distributed systems, consistent hashing is commonly used to rebalance data across nodes as we add or remove nodes from a cluster, minimizing the amount of data transfer. I can’t help but wonder if there are similar online or offline strategies that can be deployed here to make resharding easier.
Compressing checkpoint
Given the massive size of a checkpoint, it would be beneficial to compress the snapshot prior to persistent storage. Traditional lossless compression method like Gzip and LZ4 don’t end up providing a high degree of compression due to the relatively randomized nature of the training data.
This is where research on advanced quantization and pruning comes in:
Quantization is a fancy word to describe the rounding of floating numbers to lower precision, effectively reducing the bits required for storage or network transfer (i.e. quantize FP32 to FP16). Adaptive quantization means that the critical parts of the model are stored in higher precision while the less important parts are stored in lower precision, reducing lossiness of the training state.
Pruning involves zero-ing out small values in the matrices, which in turn transforms dense matrices into sparse matrices, allowing compression algorithms to perform more efficiently.
Due to the size of the snapshot, keeping all historical snapshot is simply too costly. More effective compression techniques enable retention of more historical snapshots, adding flexibility to the training process.
(It’s feels a bit meta to talk about compression when LLMs themselves are perhaps the best compression algorithm of human knowledge that’s been invented, but I digress.)
Decentralization and heterogeneous hardware
Up to this point, we assumed that distributed checkpointing is performed within a single physical data center, where close proximity of machines and high-speed interconnects facilitates efficient data transfer. A globally distributed decentralized training cluster, however, would make training — and thus checkpointing — even more challenging. It not only adds additional network latency to synchronization and limits bandwidth available for collective communication, but also complicates checkpointing logic and increases failure modes across heterogeneous hardware.
However, emerging initiatives — frameworks like OpenDiloco and HiveMind — aim to democratize AI through decentralized training infrastructure, focusing on (1) low communication with better communication topology and (2) support for heterogenous hardware. We can draw insights from peer-to-peer and edge computing infrastructures for designing decentralized communication, and from orchestration frameworks like Kubernetes and Apache Mesos for managing diverse hardware capability and availability. Engineers that are familiar with these distributed frameworks in traditional infrastructure space can potentially make meaningful contributions to ML infrastructure.
Summary
By now I have touched upon the performance, reliability, and scalability challenges of distributed checkpointing in ML training workflows. My motivation for writing this piece isn’t to paint the perfect picture of ML infrastructure or distributed checkpointing (nor am I capable of). Instead, I hope to shed some lights on the shared challenges between scaling traditional infrastructure and ML infrastructure, and maybe even spark your interest to dive deeper. Lastly and most importantly, by surfacing common grounds, I hope this post can foster more cross-disciplinary dialogues and collaborations between ML researchers and infrastructure engineers, particularly as we push the boundaries of data and compute demands in ML to new limits.
Footnote: This blogpost is written after reading open source code, papers, and blogposts, but I haven’t professionally worked on LLM training workflows. If you find any incorrect understandings, please let me know. Thank you!
References:
Checkpointing Techniques in Distributed Systems: A Synopsis of Diverse Strategies Over the Last Decades
ByteCheckpoint: A Unified Checkpointing System for LLM DevelopmentFault-Tolerant Hybrid-Parallel Training at Scale with Reliable and Efficient In-memory Checkpointing
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpointing
Check-N-Run: a Checkpointing System for Training Deep Learning Recommendation Models
Lightweight Asynchronous Snapshots for Distributed Dataflows
OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints
ExCP: Extreme LLM Checkpoint Compression via Weight-Momentum Joint Shrinking