Sync engines for the web have gained popularity in recent years. Out of curiosity, I explored this space and was amazed to discover how many companies now work on open-source sync. Electric, Zero, Instant, Triplit, Supabase, RxDB, Convex are just some examples. Some provide libraries/frameworks that you can use in your own software stack, some offer a sync engine on top of your existing Postgres database, while others are taking another stab at building a modern realtime database for the web. Then there are companies like Figma, Notion and Linear that have implemented their own sync engines. Should you build or buy, or do you even need a sync engine at all? While there's no universal answer, I want to share my learnings from building a sync engine at Figma to help make sense of this technology, highlight some technical challenges of building your own, and suggest areas to consider when evaluating existing solutions.
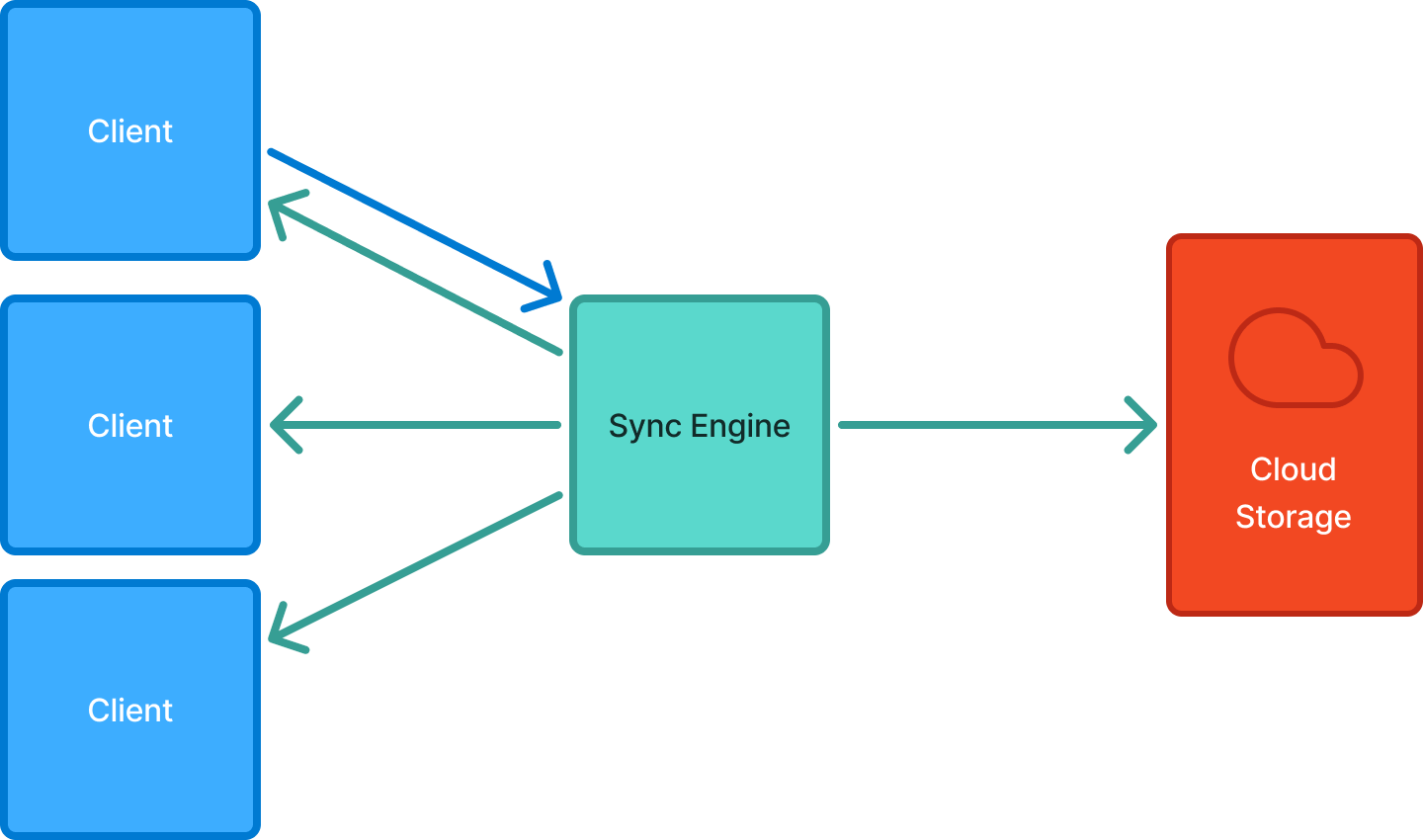
What is a sync engine?
The sync engine’s core responsibility is to synchronize data between server and clients.
From a product user’s perspective, a sync engine delivers updates in real time without having to reload the browser tab or pull-to-refresh on mobile constantly. It makes applications more reactive, performant, and collaborative. Classic examples powered by sync engines are real time messages in Discord/Slack and collaborative editing in Google Docs/Figma/Notion.
From a product developer’s perspective, a sync engine provides a declarative interface to define data models, queries, and permissions, letting developers focus on building features while the engine takes care of handling query updates. Without a sync engine, a naive implementation to add a realtime feature would require (1) adding client and server code to establish persistent connection (2) adding logic on backend to generate and send ad-hoc events at every spot that performs a database update related to your realtime feature (3) adding logic on frontend to receive events and route it to the appropriate UI component. And that’s just covering the happy path. It is tedious to write, difficult to maintain, and hard to scale.
Sync engines at Figma
One of the many reasons I joined Figma was that I was intrigued by Figma’s sync engines: Multiplayer and LiveGraph. Multiplayer syncs collaborative editing between clients, while LiveGraph syncs data from our Postgres database. For this blogpost, I will be discussing lessons learned working on LiveGraph.
LiveGraph is a read-path sync engine, where the source-of-truth lives inside the database. The read path relies solely on reading from the database, without needing to be aware of writes from clients. The read path performs sync in two stages: (1) fetching initial query result directly from the database (2) processing incremental changes from its write-ahead-log (WAL) to keep query result up-to-date. Some read-path sync engines still accept writes, but in that case they would function as a proxy layer for writing to the database. Since the database is the source-of-truth, the engine must wait for changes to be serialized to the WAL before they can be consumed, processed, and propagated to clients. The main benefit of this design is that you don’t have to give up ACID properties of relational databases. The trade-off is that this indirectness inherently introduces delay when propagating changes to clients, since data needs to pass through a few systems on the backend before reaching them.
Aside: as a point of contrast, Multiplayer is a read-write sync engine, where the source-of-truth lives inside the engine itself. The engine is responsible for receiving changes from clients, processing changes, and forwarding changes to other clients. Some changes don’t require persistence, like cursors zooming around on a shared canvas; other changes get applied to the document in-memory, which are periodically serialized and uploaded to object storage. The main benefit of this design is performance — by being the source-of-truth, it reduces latency of when other clients receive a change, especially if the sync engine server is located geographically close to its clients. The trade-off is that it doesn’t lend itself easily to relational models, unless you are willing to implement your own database engine.
State management
Unlike traditional request/response servers, sync engines are stateful, making them fundamentally harder to implement. Aside from having to keep track of things like persistent connections and query subscriptions from clients on top of unreliable networks, the state that is most tricky to keep up-to-date is query results.
Query result caches are maintained through two approaches: invalidate-and-refetch or incremental view maintenance (IVM). Both approaches depend on processing change events from the database and identifying whether one or more subscribed queries have been affected. The difference is that the former will invalidate the cache and re-query the database to get the latest result, while the latter will apply the change to the existing query result without a roundtrip to the database.
The initial implementation of LiveGraph used an IVM-based approach to update query results, with the benefit of reducing database load. For example, given the following subscribed query:
SELECT * FROM comments WHERE comments.file_id = 123;
When a new comment is added to the comments table for a given file, instead of refetching all comments, we could simply add the row to the in-memory query result set.
A more subtle benefit is that it preserves causal consistency since change events from the database reflect the true order of state change, whereas invalidation and refetch is inherently indeterministic due to network delays and the scheduling of query execution on the database.
IVM becomes tricky to implement with complex queries (it’s a heavily researched space in academia, after all). Over time, we encountered use cases like pagination and aggregations that couldn’t easily be supported without pouring a ton of engineering resources into it.
The other hard thing about this approach is handling the thundering herd problem during deployment, since the server has to re-issue all the queries against the database to populate its cold cache. Extending phased rollout to spread the database load can only get us so far. Pre-warming the in-memory cache does not protect it from unexpected crashes.
Ultimately, LiveGraph was re-architected to offload query results to a separate cache and switched to an invalidation-and-refetch approach, which made it easier to maintain and scale. I recommend checking out this blogpost to learn about the redesign (Asana’s WorldStore also went through a similar evolution). Finally, I recommend watching this talk to learn about Linear’s local-first sync engine architecture; which leveraged client-side storage to reduce server-side state management.
Query matching
Sync engines route updates to affected queries, and it’s crucial that this query matching step is executed efficiently to keep latency under control. Iterating through all subscribed queries for every update and performing a full “query-update intersection analysis” would be too expensive. We need something that’s near-constant time instead. LiveGraph achieved this with query hints.
Let’s go back to our example:
SELECT * FROM comments WHERE comments.file_id = 123;
We can analyze this query’s predicate and generate a hint that maps from comments:file_id:123 to this query upon subscription. This way, whenever we receive a change event for the comments table with file_id field equal to 123, we can route the change to the query. This approach is analogous to inverted indices by mapping from data to the subset of queries affected by it.
It’s important to note that while it’s fine to have false positives (engine can just ignore the change event if it’s deemed irrelevant), false negatives would result in missing updates. Because LiveGraph’s objects and views are statically defined and deployed server-side, we can leverage the fact that query shapes are known in advance to optimize query hints. Making this work for complex queries or arbitrary queries from clients would be a lot more challenging.
Permissions
A core piece of the sync engine that’s not often discussed is the permission system, which is hard in a few different ways.
A permission system applied to sync engines can be thought of as a filter to determine whether a change event should be propagated to a client. The tricky part is that permission logic is business logic, especially in enterprise applications where ACLs tend to be complex and granular. Evaluating permission logic requires additional data dependencies as inputs beyond the change event itself. This means these data dependencies must be kept in sync as well, even if they are not data that clients requested. To ensure correctness of permission evaluation, database transaction boundaries must be respected. This requires waiting for an entire transaction to be processed before running permission checks, which can delay client synchronization for large transactions. As we ported more features over to LiveGraph, permission logic introduced additional latency and memory overhead.
Another hard thing about permissions is maintaining cross-system consistency. When LiveGraph was first implemented, we already had a permission system in the main HTTP backend. This permission logic was implemented imperatively at the time. To achieve feature parity with the existing permission system at the time, LiveGraph replicated the same permission logic. Product engineers had to update the permission logic in both systems written in two different languages every time a change to permissions was made, which was error-prone and easy to get out-of-sync. To systematically address this issue, Figma built a custom declarative DSL and permission engine that streamlined permission evaluation using a policy-based approach (recommend this blogpost for more details).
If you plan to build or adopt a sync engine for your application, it’s a good idea to evaluate the path for unifying permission logic (some sync engines do not need a permission system: in Multiplayer’s case, all clients subscribed to a document can receive all updates for that document, so permission is trivialized).
Versioning and schema compatibility
Whether your sync engine uses SQL, GraphQL or a proprietary query language, the underlying schema of the data model will inevitably evolve with the business (e.g. new data models get added, existing fields get renamed, etc.). Just like traditional backend applications that need to be compatible with database schema changes, sync engines do as well. Additionally, sync engines face the challenge of maintaining client-server schema compatibility, since users may keep browser tabs open for extended periods before closing or refreshing them.
With LiveGraph, whenever the schema is updated server-side, the new schema is added to the engine upon deploy, allowing it to simultaneously support both old and new clients based on the version of schema they have. This approach worked for us because LiveGraph’s client-side implementation was in-memory only, eliminating the need to worry about schema compatibility with the client’s database.
When evaluating sync engines, especially those designed for offline-first applications that persist data on the client, it’s useful to understand how schema changes are supported on the client. Does the client’s local database get re-bootstrapped, or do schema migrations run on top of existing data? Some sync engines only support a subset of migration operations; make sure you understand the behavior and limitations.
Conflict resolution and local-first software
When we implemented LiveGraph, we were focused on improving client-side reactivity, reducing database load, and optimizing developer ergonomics for product engineers. Offline support was not a design goal at the time. This means optimistic updates were sufficient for our needs, and we could offload the hard problem of conflict resolution to the database.
With the rising popularity of local-first software, most generic sync engine solutions support offline mode. This increases the frequency of conflicts and introduces more complex scenarios that require resolution. Some engines provide a set of CRDTs that you can choose from depending on your application’s needs, others keep it simple with last-write-wins. If you are looking to adopt an existing sync engine solution with offline support, make sure its conflict resolution aligns with your application semantics.
Scaling
When it comes to scaling a sync engine, it’s not too far-fetched to say that all laws of the universe (except for Moore's law) are working against you. The change event queue latency can exceed SLA as write volume increases and processing cannot keep up. The cache can OOM if client subscription spikes or memory resources are not carefully monitored; or the engine may slow down due to cache thrashing if you have an eviction policy in place. Large transactions in the database can result in unexpected latency spikes. Local storage can exceed browser storage limits. The database may eventually get sharded, so there could be cross-shard transactions to worry about. Even the programming language can work against you if it starts to spend too much of its time in garbage collection, given how compute- and memory-intensive sync engines are. To scale LiveGraph effectively, setting up comprehensive observability across the entire stack (client, engine, database) is essential to allow us to proactively identify bottlenecks and manage capacity.
It’s hard to tell how well a generic sync engine scales just by reading docs, since every application has different requirements and usage patterns. When evaluating, load-testing with production-like traffic patterns up front and assessing latency, correctness, resource utilization and storage limitations is a good idea if feasible.
Conclusion
Sync engines introduce familiar concepts (reactive programming and stream processing) to the web, with the added benefit of enabling local-first software. Working on sync engines firsthand has both humbled me with their complexity and inspired me with their potential to transform web and developer experiences. It’s exciting to see companies working on commoditizing this technology, and coming up with novel approaches.
When assessing sync engine solutions for your application, it’s useful to ask yourself these questions upfront:
What is the latency requirement for syncing data between clients?
Am I trying to adopt a sync engine solution for an existing application/database? or building a new business/product for the first time?
How much data is expected to be synced on clients?
How often does my synced data get updated? Is my application write-heavy or read-heavy?
What is the complexity of my application’s query patterns that need to be synced?
Is there an existing permission system in place? How granular is the application’s permission model?
How important are offline support and conflict resolution?
Does syncing data improve my application’s user experience, or is it overkill?
Knowing the answers to these questions will help you more effectively evaluate which open-source and/or vendor solution fits your use cases, if rolling out your own is necessary, or if you need sync at all.
Happy syncing!
Thank you Chris Lewis, Rudi Chen, and Slava Kim for reviewing drafts of this blogpost.